In non-uniform memory access (NUMA) systems, Access time to data depends on whether the data is located on local memory or off-socket memory. [numactl] is a tool to control which nodes are used to allocate memory for a program. It can speed up the execution of a program reasonably if threads use data in the local memory more than data in other node. This post is a quick summary of the memory allocation options of numactl. You may refer to this blog if you are looking for an overview of the tool.
--interleave=nodes, -i nodes
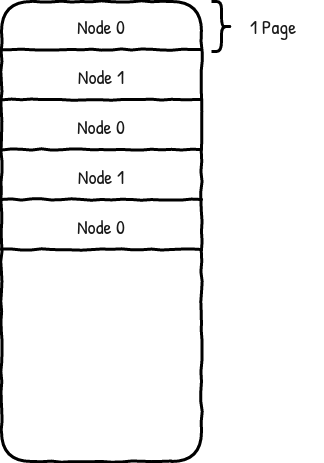
Allocates memory on specified nodes by alternating at each page (first page in node 0, the second page in node 1, third page in node 0 and so on). This layout is not guaranteed as it can allocate on other nodes if it is not possible to allocate on specified nodes.
Note: nodes can be set as all to select all nodes in the system.
This is how I imagine the virtual memory looks like with this policy when node 0 and node 1 are used.
--membind=nodes, -m nodes
It is a strict policy, fails if it cannot allocate on specified nodes. However, man page is not clear on what happens when more than 1 node is given in the arguments. Does it try to split evenly among nodes? or try to allocate on the first node and go to other nodes only the allocation on the first node fails? I did a quick experiment and couldn't find a pattern. It seems like the choice is completely arbitrarily. I guess we shouldn't rely on any distribution between specified nodes.
--preferred=node
Similar to membind but it accepts only one node as an argument. It tries to allocate all memory on that node, can allocate on others in case of a fail.
--localalloc, -l
This is the default policy and I think it's the most confusing one. man page says:
Falls back to the system default which is local allocation by using MPOL_DEFAULT policy.
It uses the default allocation policy of the system. Resources on the Internet says it is the First-touch policy in Linux. I don't know about other systems. First-touch policy means that the memory is not allocated in the physical memory right away when we malloc'ed. The real allocation happens when a thread tries to read or write on those allocated space, triggered by a corresponding page fault.
I used the following code to test this behavior.
int N = 100000000;
int IT = 100;
int* arr = new int[N];
// Initialize the array
#pragma omp parallel for schedule(static)
for(int i = 0; i < N; i++)
{
arr[i] = i;
}
// Do some calculations over the array
for(int i = 0; i < IT; i++)
{
#pragma omp parallel for schedule(static)
for(int j = 0; j < N; j++)
{
arr[j] *= j;
}
}
We allocate around 400 MB of memory, initialize with some numbers and then we do some calculations on those memory locations for some time. Calculation part is parallelized with OpenMP so the first half is processed by a thread and the second half is processed by another thread. I did the same thing with initialization but in some trials, I removed the first omp pragma to allow only one core to do initialization. This will be referred to as serial array initialization.
Other experimental setup details:
- The code is executed on only 2 cores.
- I pinned OMP_PLACES=cores and OMP_PROC_BIND=close.
- The local node of cores 1-7 is node 0 and 8-15 is node 1
- Specified the active cores with taskset -c command.
- The size of the memory allocated on each node is found with numastat utility.
The results are given in the table below. It looks like the result is consistent with first-touch policy: Memory is allocated on the node that initializes that part (i.e. the node that touches the memory first).
| Experiment | Allocated Memory on on node 0 (MB) |
Allocated Memory on node 1 (MB) |
|---|---|---|
| Serial array initialization, parallel execution on core 0 and 1 | 383.8 | 0 |
| Serial array initialization, parallel execution on core 0 and 8 | 383.8 | 0 |
| Parallel array initialization, parallel execution on core 0 and 1 | 383.8 | 0 |
| Parallel array initialization, parallel execution on core 0 and 8 | 193.7 | 192.1 |
Comments