Grouplens recently published Movielens 25m dataset, a successor of Movielens 20m dataset that is heavily used in the data science field. In this post, I'll do a quick analysis of the dataset and compare it with movielens20m.
Datasets come in several files. I'm just going to use the following ones:
- movies.csv Contains id, movie title, and tag information.
| movieId | title | genres |
|---|---|---|
| 1 | Toy Story (1995) | Adventure |
| 2 | Jumanji (1995) | Adventure |
| 3 | Grumpier Old Men (1995) | Comedy |
| 4 | Waiting to Exhale (1995) | Comedy |
| 5 | Father of the Bride Part II (1995) | Comedy |
- ratings.csv is the main data file I'm interested in, it contains the rating matrix. The rating matrix is a big matrix where rows represent users, columns represent movies and the values inside the matrix are rating values between 0.5-5 for a particular user-movie pair. The names of the datasets come from this file, Movielens 20m means that the rating matrix has 20 million ratings. This is what the file looks like:
| userId | movieId | rating |
|---|---|---|
| 1 | 296 | 5.0 |
| 1 | 306 | 3.5 |
| 1 | 307 | 5.0 |
| 1 | 665 | 5.0 |
| 1 | 899 | 3.5 |
- tags.csv has user-generated tags, I'll use this file to create a tag cloud.
- links.csv is a mapping file that includes movielens identifiers and their corresponding IMDb identifiers. I will use it to get posters of the top-rated movies.
The code I've used to get all the following stats and plots is located here.
Basic Statistic Comparison
| - | Movielens 20M | Movielens 25M |
|---|---|---|
| Rating count | 20000263 | 25000095 |
| User count | 138493 | 162541 |
| Movie count | 26744 | 59047 |
| Density of the Matrix | 0.00540 | 0.00260 |
| Max # movies rated by a user | 9254 | 32202 |
| Min # movies rated by a user | 20 | 20 |
| Average # movies rated by a user | 144.41 | 153.81 |
| Max # users rated a movie | 67310 | 81491 |
| Min # users rated a movie | 1 | 1 |
| Average # users rated a movie | 747.84 | 423.39 |
-
There is a person on the Earth, that watched 32202 movies and rated them on the Movielens platform. That is probably not true, considering that watching all those movies would probably take around 6-7 years but that is what the data says so, I'm not the judge.
-
Users with less than 20 ratings are filtered out so they do not appear on the matrix. README file confirms this statement: "Users were selected at random for inclusion. All selected users had rated at least 20 movies."
-
Another thing to note here is that the 25M dataset is a lot more sparse due to the increased number of movies. The New dataset has 25 % more ratings but has two times over movies.
-
The movie rated most has over 80k ratings and that movie is Forrest Gump.
Rating Distributions
Rating histograms show how high and low scores are distributed among movies and users.
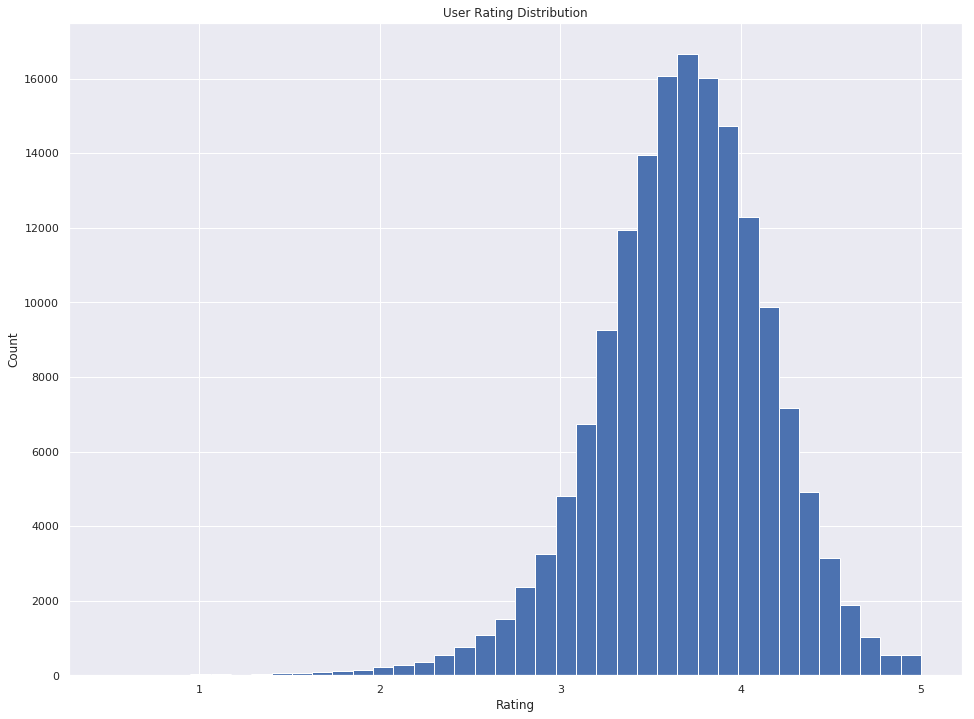
It looks almost like a normal distribution, the things are different in the movies' side, however.
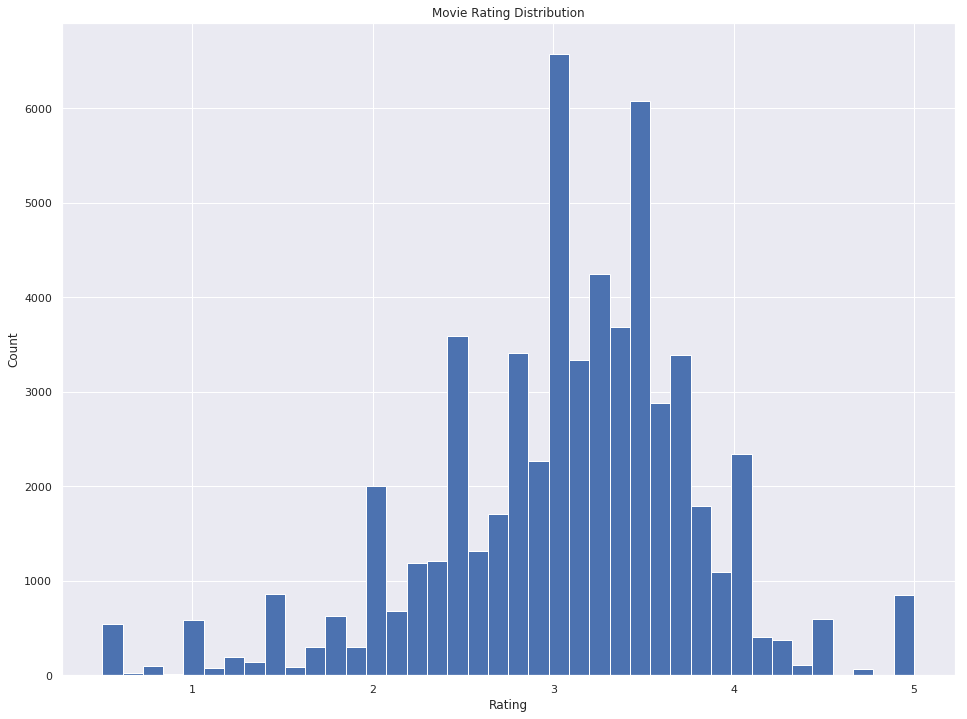
Movielens top 20
To get this list, I look for movies with more than 2000 ratings. Otherwise, movies with only one 5-star rating would be the top movies. Here is the list with their averaged rating score:
20 - Pulp Fiction (1994)
Score: 4.189

19 - Double Indemnity (1944)
Score: 4.194

18 - North by Northwest (1959)
Score: 4.197

17 - Paths of Glory (1957))
Score: 4.199

16 - Lives of Others, The (Das leben der Anderen) (2006)
Score: 4.200

15 -Third Man, The (1949)
Score: 4.201

14 - Sunset Blvd. (a.k.a. Sunset Boulevard) (1950)
Score: 4.207

13 - Casablanca (1942)
Score: 4.207

12 - Spirited Away (Sen to Chihiro no kamikakushi) (2001)
Score: 4.212

11 - Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb (1964)
Score: 4.216

10 - One Flew Over the Cuckoo's Nest (1975)
Score: 4.219

9 - Fight Club (1999)
Score: 4.228

8 - Rear Window (1954)
Score: 4.238

7 - 12 Angry Men (1957)
Score: 4.243

6 - Schindler's List (1993)
Score: 4.248

5 - Seven Samurai (Shichinin no samurai) (1954)
Score: 4.255

4 - Godfather: Part II, The (1974)
Score: 4.262

3 - Usual Suspects, The (1995)
Score: 4.284

2 - Godfather, The (1972)
Score: 4.324

1 - Shawshank Redemption, The (1994)
Score: 4.414

Tag Cloud
Lastly, I would like to share the tag cloud created from user-generated tags. In the Movielens platform, a user can enter any tag to a movie. I removed popular genre tags like Comedy, Romance, Horror etc. to get a more interesting result.
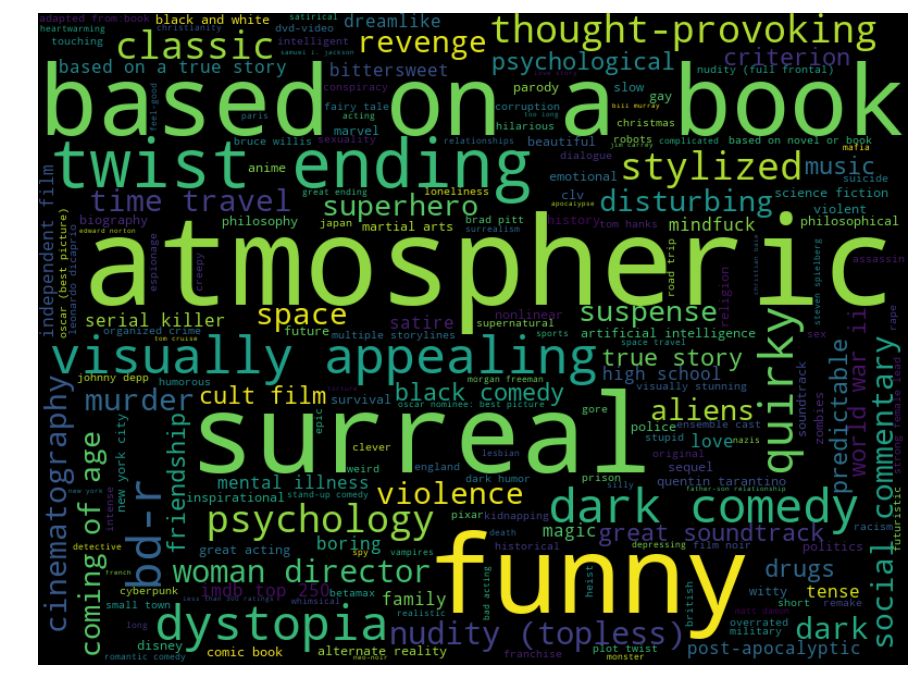
I share python notebook in case you would like to play with it.
Comments